
Stop overpaying for data. Learn to build a production-grade streaming analytics platform using Kafka, Flink, and Spark ML for under $300/month.
Why Your Real Time Data Pipeline is Bleeding Cash
Let’s be honest: most “real-time” data platforms are just expensive ways to set money on fire. I’ve seen CTOs lose sleep over $50k monthly cloud bills while their data still arrives with enough lag to make a 1990s dial-up modem look fast.
In the high-stakes world of streaming analytics, speed is money. In Southeast Asia alone, we saw 1.93B mobile game downloads in Q1 2025, but only a fraction converted to revenue—largely due to monetization gaps where players churned before the system even realized they were frustrated. Meanwhile, in fintech, failing to meet real-time AML requirements can land you a S$960K penalty faster than you can say “out of memory error.”
As a crisis specialist who’s spent way too many 3 AMs fixing broken pipelines, I’m here to tell you that you don’t need a BigTech budget to achieve BigTech results. You just need to stop building like a billionaire and start building like a pragmatist.
1. The “Hidden Burn”: Why Your Pipeline is Broke
High-performance distributed systems shouldn’t always require a six-figure salary to maintain. Most companies overspend because of three specific “facepalm” moments:
- Ghost Capacity: Running clusters at 15% utilization “just in case” of a spike. You’re essentially paying for a 24/7 security guard for a building that’s only occupied on Tuesdays.
- The “Throw Money at It” Fallacy: It’s easier to click “upgrade instance” than it is to fix a poorly modeled query or pipeline strategy. This laziness has a 10x multiplier on your TCO (Total Cost of Ownership).
- The Silent Egress Tax: NAT Gateways and inter-AZ traffic are the pickpockets of AWS. If you aren’t careful, routing your data can cost more than processing it.
2. The Power Trio: Kafka, Flink, and Spark ML
There is no “perfect” stack, but if you want to balance latency with your bank account, this is the combo to beat.
| Component | The “Pro” Move | The “Money Pit” Trap |
| Kafka | Use for high-throughput ingestion and event replay. | Leaving retention on “Infinite” using expensive SSDs. |
| Flink | Millisecond latency for stateful transformations. | Ignoring RocksDB state bloat; profile your memory early! |
| Spark ML | Mature MLlib for heavy-duty feature engineering. | Single-record inference. (Seriously, don’t do this). |
The Polyglot Strategy: Right Tool, Right Language
Efficiency isn’t just about infra; it’s about using languages for what they do best. In a high-performance streaming analytics setup, I use Scala with Flink for the heavy-duty, type-safe processing where performance is non-negotiable. For the intelligence layer, I stick with Python for Spark ML; it offers the best ecosystem for data science, and since Spark’s inner backend (Tungsten) executes on the JVM, you get Python’s productivity with near-native speed. Finally, I use Java Spring Boot for the UI and API layer—it’s the battle-hardened standard for building responsive, secure interfaces that can serve real-time alerts to users without skipping a beat.
The Secret Sauce: Use performance optimization techniques like switching from single-record inference to batched scoring in Spark. I’ve seen this move alone drop per-record latency from 950ms to 12ms—a literal 79x throughput boost on the exact same hardware.
3. Case Study: PatternAlarm (Real-Time Fraud Detection)
I built PatternAlarm to prove a point: you can run a production-grade fraud detection engine processing 10,000+ events per minute for about the price of a mid-tier gym membership.
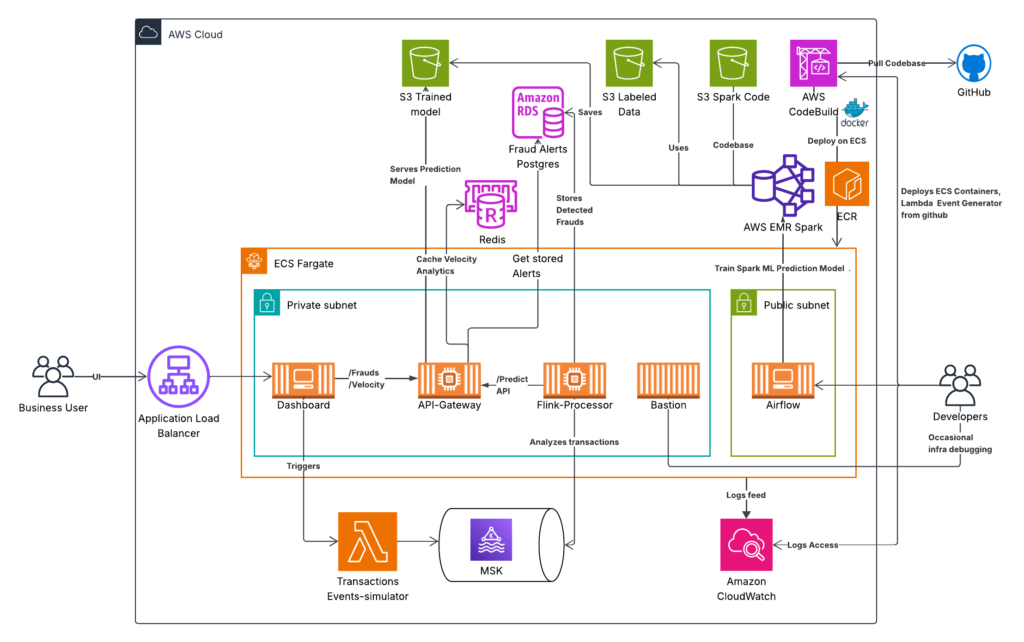
It handles bronze-silver-gold data transformations across gaming and fintech sectors with a sub-3-second end-to-end latency.
The Architecture Breakdown
- Ingestion: AWS Lambda feeding into Amazon MSK (Managed Kafka).
- Processing: Scala-based Flink jobs running on ECS Fargate.
- Intelligence: A RandomForest model via Spark ML boasting 97.5% accuracy.
- Orchestration: Airflow + EMR Serverless for sporadic model retraining.
The Monthly Bill (~$280 Total):
- MSK (t3.small): $72
- Fargate (Auto-scaling): $110
- EMR Serverless (Training): $45
- The Rest (S3, CloudWatch, API Gateway): $53
Get the Code: If you want to see how this works under the hood, I’ve open-sourced the entire implementation. Check out the PatternAlarm project on GitHub to see the Terraform scripts and Flink logic for yourself.
4. Cost Optimization: Practical Wins
If you’re looking for a bottleneck fix, start here:
- Storage Tiering: Kafka brokers love expensive local storage. Archive your segments to S3 after 24 hours. You’ll slash storage costs from $0.10/GB to $0.023/GB instantly.
- Network Topology: Keep your processing in the same VPC and AZ where possible. Use VPC Endpoints for S3; otherwise, you’re paying $0.045/GB just to talk to your own data.
- Scale to Zero: Use ECS Fargate for your consumers. If the traffic drops at night, your bill should too. Don’t pay for idle CPU cycles.
- Understand Your Data: Check out this guide to data systems to ensure you aren’t using a sledgehammer to crack a nut.

5. When to Walk Away
I love this stack, but I’m not a zealot. Don’t build a streaming analytics platform if:
- You’re low-volume: If you’re under 1,000 events/minute, a simple Lambda + SQS setup is cheaper and easier.
- Latency isn’t critical: If a 10-minute delay won’t kill your business, stick to pure batch ETL. It’s simpler to debug and cheaper to run.
- Stateless logic: If you’re just doing simple “If A then B” transforms without needing history (state), Flink is overkill.
The Bottom Line
Building a real time analytics platform isn’t about having the biggest budget; it’s about having the best architecture. Profile your bottlenecks, batch your ML inference, and use serverless components to handle the heavy lifting.
Would you like me to help you draft the Terraform configuration for an auto-scaling Fargate consumer to get you started?